Deep Learning: Architecture And Algorithms
Faculty Mentor:
Dr. Praveen Kumar Gupta
Student Name:
Justin Devassy (MCA - 2nd Year)
Abhishek Bhardwaj(MCA - 2nd Year)
ABSTRACT
During recent years, deep learning has become a buzzword in the tech world. Deep learning has changed the entire world over
the past few years. Every day, more applications depend on neural networks in fields of healthcare, object detection, finance,
human resources, retail, earthquake detection, and self-driving cars. As for existing applications, the results have been
steadily improving. Deep learning also referred to as deep neural learning or deep neural network.
1. WHAT IS DEEP LEARNING?
Deep learning is a machine learning method that takes in an input A and uses it to predict
an output of B. Deep learning processes data and creates patterns for use in decision making. For example let say that inputs are images of dogs and cats, and outputs are labels for those images (i.e. is the input picture a dog or a cat). If an input has a label of a dog, but the deep learning algorithm predicts a cat, then the deep learning algorithm will learn that the physiognomy of the given image (e.g. sharp teeth, facial features) are going to be associated with a dog.
1.1 Real-world examples of deep learning.
- Autonomous Vehicles: While some models pin-point pedestrians, others are proficient at identifying street signs and some good at mapping roads. A single car can be trained by millions of AI models while driving down the road on its own. Example: Tesla
- Language Identification: Deep learning is at a preliminary stage where smartphones can differentiate between different dialects. For example, a machine will compute and decide that an individual is speaking in English. It will then judge based on the dialect.
- Face Recognition: Every time you upload a photo to Facebook, the platform uses facial recognition algorithms to identify the people in that image and then help tagging the person using facial features. Certain governments around the world use face recognition technology to identify and catch fugitives. You can now even unlock smartphones with your face.
- Image Recognition: One of the greatest feats
of deep learning is the ability of software to identify places, people,
writing and actions in images and in combination with a camera and artificial intelligence software to achieve image recognition. Example: Google Lens which can identify and search objects.
1.2 Some famous Deep Learning Architecture
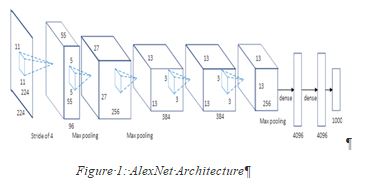
- AlexNet: AlexNet is the first deep learning architecture that was introduced in deep learning by Geoffrey Hinton and his colleagues. It is a simple yet robust network architecture, which helped pave the way for revolutionary research in Deep Learning. The things which set apart this model are the scale at which it performs the task and the use of GPU high computation power for training rather than CPU. In the 1980s, CPU was used for training a neural network. Whereas AlexNet boosted the training 10 times just using GPU.
- GoogleNet: Google Net is a class of architecture designed by researchers at Google. Google Net was the winner at ImageNet 2014, where it proved to be a powerful model. In this architecture, along with going deeper (it contains 22 layers in comparison to VGG (Visual Geometry Group) which had 19 layers), the researchers also made a novel approach called the Inception module.
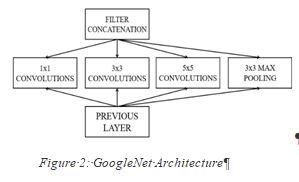
In a single layer, multiple types of feature extractors
are present and removing a single lead leads to a huge decrease in
accuracy. This indirectly helps the network greatly to perform better,
as the network at training itself has many different options to choose
from when solving the task. It can either choose to convolve the input, or to pool it directly.
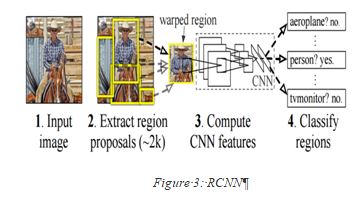
2. RCNN (Region-Based Convolutional Neural Network
Region-Based CNN architecture is said to be the most significant of all the deep learning architectures
that have been applied to object detection problems. To solve detection problems,
what RCNN does is to attempt to draw a boundary box over all the objects present in the image, and then recognize what object is which the image.
<
3. WHY IMAGE RECOGNITION?
Image recognition is a great work for developing and testing machine learning approaches
for a better tomorrow. But how do we do it? How does the brain translate the physical object
in front of our eyes into a mental model of our surroundings. We dont think anyone knows exactly
how our mind does it. The point is, its seemingly easy for us to do so easy that we dont even
need to put any conscious effort into it but difficult for computers to do so.
3.1 Some Examples of Image Recognition Applications
Google Lens uses Tensor Flow which is Google's open-source machine learning framework. TensorFlow helps connect images to the words that best describe them. The algorithms then connect those labels to Google's Knowledge Graph, with its tens of billions of facts of image clicked and available over the google search engine.
Google Lens: Google Lens is animage recognition technology developed by Google, designed to bring up relevant
information related to objects it identifies using visual analysis based on a neural network. First announced during Google I/O 2017 October 4, it was first provided as a standalone app, later being integrated into Android's standard camera app.
- The way we use our cameras is not the only thing thats changing: the tech behind cameras is evolving too. As hardware, software, and AI continue to advance.
- To make this possible, Lens can read and let you act with the words you see. For example, you can point your phone at a business card and add it to your contacts or copy ingredients from a recipe and paste them into your shopping list.
- Sometimes, its hard to distinguish between similar-looking characters like the letter "o" and zero. To do this, Lens uses language and spell-correction models from Google Search to better understand what a character or word most likely is just like how google search knows to correct bannana to banana, Lens can guess c00kie is likely meant to be cookie.
- Google lens uses a deep learning library called TensorFlow that consist of multiple machine learning algorithms.
3.2 WHAT IS TENSORFLOW?
Currently, the most famous deep learning library in the world is Google's TensorFlow. Google product uses machine learning in all of its products it produces to improve the search engine, translation, image captioning and recommendations hence making it efficient. A couple of years back, deep learning started to outperform all other machine learning algorithms when giving a massive amount of data. Google saw it could use these deep neural networks to improve its services to predict and give users a much better experience when using their products:
- Gmail
- Google Photo
- Google search engine
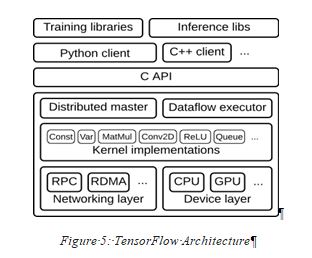
TensorFlow Architecture
TensorFlow architecture works in three parts:
- Pre-processing the data
- Build the model
- Train and estimate the model
- It is called TensorFlow because it takes input as a multi-dimensional array, also known as tensors.
List of Prominent Algorithms supported by TensorFlow
Currently, TnsorFlow 1.14 has a built-in API for:
- Linear regression: tf.estimator.LinearRegression
- Classification: tf.estimator.LinearClassifier
- Deep learning classification: tf.estimator.DNNClassifier
- Deep learning wipe and deep: tf.estimator.DNNLinearCombinedClassifier
- Booster tree regression: tf.estimator.BoostedTreesRegressor
- Boosted tree classification: tf.estimator.BoostedTreesClassifier
4. CHALLENGING PROBLEMS IN IMAGE RECOGNITION
Major Issues in Image Processing are Image Filtering, Image Restoration, Image Registration, Image Fusion, Image Segmentation and Image Classification.
- Recognition: A model is trained and evaluated on a dataset that is randomly split into training and test sets. The test set thus has the same data distribution as the training set, as they both are sampled from the same range of scene content and imaging conditions that exist in the dataset. However, in real-world applications, the test images may come from different data distributions from those which were used in training. Such a gap in data distribution can lead to huge drops in accuracy over a wide variety of deep network architectures.
- Comprehensive Scene Understanding: In addition to problems related to training data and generalization, an important factor which is comprehensive scene understanding i.e. recognizing and locating objects to objects relations and acquiring border understanding of scenes which requires knowledge beyond object identity and location.
- Image Quality: Image quality is one of the main factors which are kept in mind while training model as input images are of relatively high quality. Low-resolution, other image quality distortions may affect performance. Low-resolution images consist of very limited information which cannot be used to identify or detect image as most of the details are lost. This can drop down the recognition rate drastically.
5.OPPORTUNITIES
As we know image processing is a promising domain. Image Recognition has vast applications in the field of image analysis, pattern recognition, machine learning, and computer vision domains.
- Advances in image processing and artificial intelligence will involve diagnosing medical conditions, performing surgery, and automatic driving all forms of transport. With increasing power and refinement of modern computing, the thought of computation can go so much on the far side of the current limits, as in future image processing technology can advance severalfold.
- Using large scale homogeneous cellular arrays of straightforward circuits to perform image processing tasks and to demonstrate pattern-forming phenomena will be a rising topic. The cellular neural network is an implementable alternative to fully connected neural networks and is growing into a paradigm for future imaging techniques. The usefulness of this technique has applications in the areas of silicon retina, pattern formation, prosthetics, etc.
6. USES
- Disability - Robotics navigation systems for the visually challenged will create real-time 3D maps. Vibrating sensors would convey instructions to the aiding navigation.
- Defense - Military robots with a greater vision sense can carry out, with help of real-time footage, remote rescue operations.
- Traffic- Drones will shoot and process real-time images of traffics and send them back to your mobile consequently. You can drive safely and bypass congestions.
- Crime - Artificial intelligence software can scour through millions of photographs and videos in a few minutes to nab a fugitive on the run.
- Healthcare- 3D images can help doctors to perform surgeries of delicate areas like inside veins which they otherwise could not have.
7. CONCLUSION
Image recognition is used in various applications like improving 3D medical imaging which can help doctors to perform critical surgeries, its biggest application is the identification of fugitives and criminals on run. But also, facial recognition can raise privacy issues of personal as individual's face in the street can be identified using a face recognizer and identified images from social network sites like Facebook or LinkedIn, then it becomes possible not just to identify that individual, however conjointly to infer further, and additional sensitive, data. In Image recognition, a model which is trained is limited to it's provided training set which results in accuracy issues in our model and to train well-defined model it requires millions of images or data and higher amount of Computation processing.
8. REFERENCES
- [1]Krizhevsky, Alex et al, ImageNet Classification with Deep Convolutional Neural Networks, Published with Semantic Scholar, 2012
- [2]Gupta, Praveen Kumar et al, Framework for Handling Uncertainty through Temporal Databases, IJEECE, Vol 4, issue 1, pp 9-13, 2015
- [3]https://www.ncbi.nlm.nih.gov/pmc/
articles/PMC47654/
- [4]https://towardsdatascience.com/deep-learning-for-image-classification-why-its-challenging-where-we-ve-been-and-what-s-next-93b56948fcef
- [5]https://www.tensorflow.org/guide/extend
/architecture
- [6]https://www.microsoft.com/en-us/research/lab/microsoft-research-asia/articles/image-recognition-current-challenges-and-emerging-opportunities